
SQLクエリを高速化するための手法の一つにインデックスがあります。インデックスには、単一のカラムに設定する「単一インデックス」だけでなく、複数のカラムに設定する「複合インデックス」もあります。
本記事では、MySQLにおける複合インデックスの動作を理解し、なぜ2つ目のカラム単体では検索の高速化ができないのかを解説します。
※ 簡単のため、本記事で扱う複合インデックスは2つのカラムのみを対象とします。(MySQLでは最大16カラムまで設定可能です)
結論
タイトルにある結論を一言で言うと、複合インデックスは左端のカラムを基準にソートされているため、2つ目のカラム単体ではインデックスが効かない ということです。
以下、詳しく解説していきます。
- 複合インデックスとは
- インデックスはどういうデータ構造で管理されている?
- 複合インデックスの2つ目のキーだけで検索するとどうなるか?
複合インデックスとは
複合インデックスは、複数のカラムに対して設定されたインデックスを指します。
CREATE INDEX インデックス名 ON データベース名 (col1, col2);上のコマンドでは、col1, col2 の2つのセットに対して1つのインデックスを設定するコマンドになります。
複合インデックスを利用する際の注意点として、検索キーに左端のカラムがふくまれていないと検索が高速化されないという点が挙げられます。
// 高速に検索できる例
SELECT * FROM データベース名
WHERE col1 = 'XXX' and col2 = 'YYY';
// 高速化できない例
SELECT * FROM データベース名
WHERE col2 = 'YYY';インデックスはどういうデータ構造で管理されている?
単一インデックスの場合
インデックスは「B+ツリー構造」という二分木の進化系みたいなデータ構造で管理されています。
簡単のため、単一インデックスのB+ツリーについて説明します。
B+ツリーはルートノード、中間ノード、リーフノードの3種類の要素で構成されています。下のイラストでいえば、
- 一番上のノードが ルートノード
- 真ん中の層のノードたちが 中間ノード
- 一番下のノードたちが リーフノード
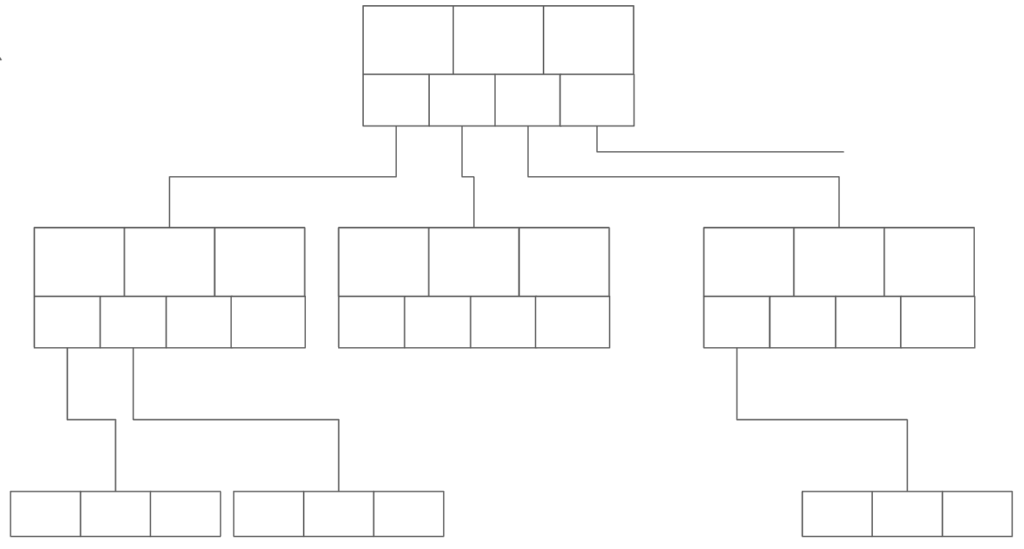
このB+ツリーのノードは、上の3つのブロックがセパレータキーとよばれる値を管理しており、その下の4つのブロックが下の階層のノードへのポインタを格納する仕組みになっています。
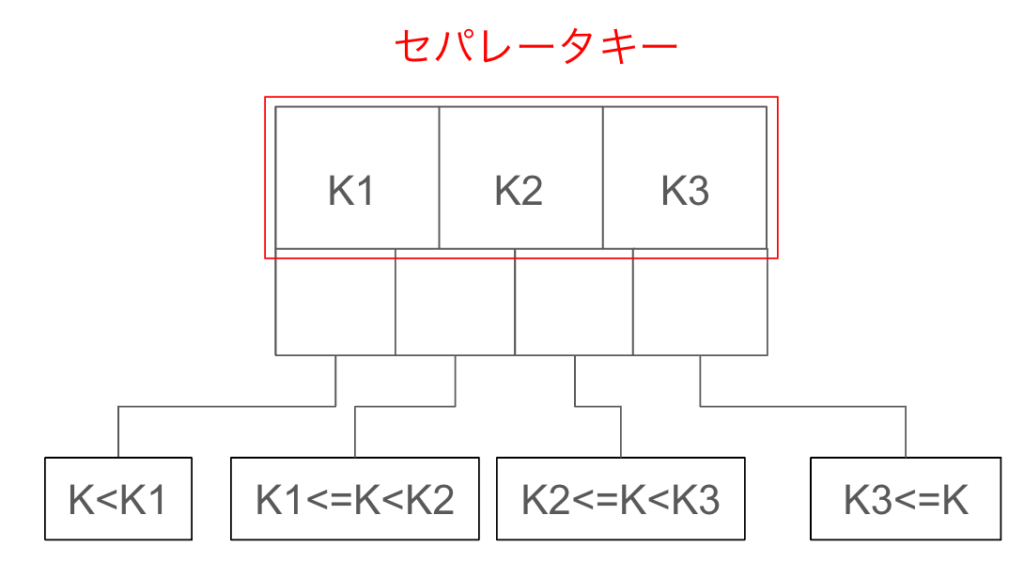
Kが検索された場合、セパレータキーの値と比較され、条件を満たす下の階層ノードのポインタへと処理が進みます。
例) Kが K1<K<K2 を満たす場合、左から2番目のポインタへ進んで検索処理が実行されます。
ここで重要なのは、セパレータキーはソートされた状態で管理されていると言うことです。上記のセパレータキーで言えば、以下の関係が成り立っています。
K1<K2<K3
複合インデックスの場合
複合インデックスのB+ツリーの場合、各ノードのセパレータキーが1つの値ではなく、二つの値のペアとして格納されます。
CREATE INDEX test_idx ON test_table (s, t);上記のようにカラム s, t に関する複合インデックスを設置した場合、以下のようなノード構成になります。
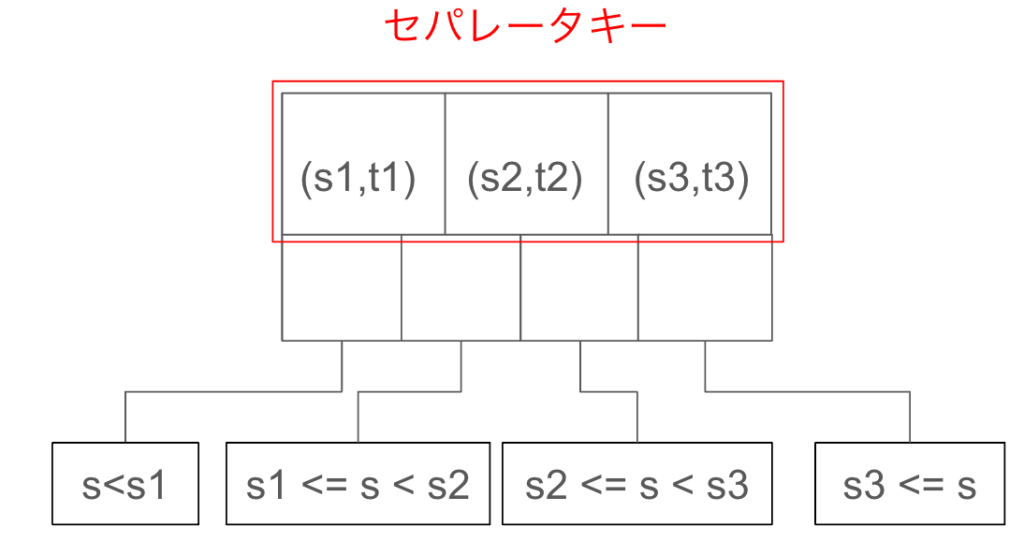
ここで重要な点として、セパレータキーは一番左のキーに関してソートされて管理されているということです。
複合インデックスの2つ目のキーだけで検索するとどうなるか?
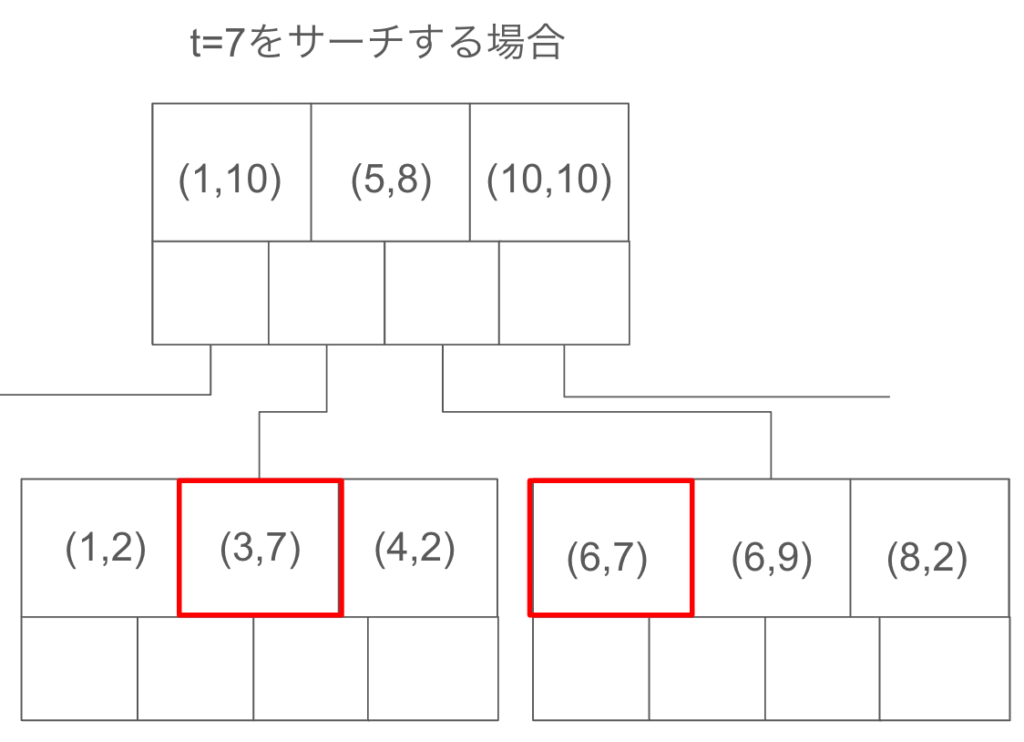
複合インデックスの一番左のキーの値でソートされているため、複合インデックスを設定したときと同じ並びで検索した場合は、以下のようにピンポイントで該当箇所を取得することが可能になります。
カラム s の値でソートされているため、二分探索木と同様で、他のノードを探索する必要がありません。そのため、計算量は $O(logN)$ 程度で済み、とても高速に検索できます。
select * from test_table
where s=3 and t=7;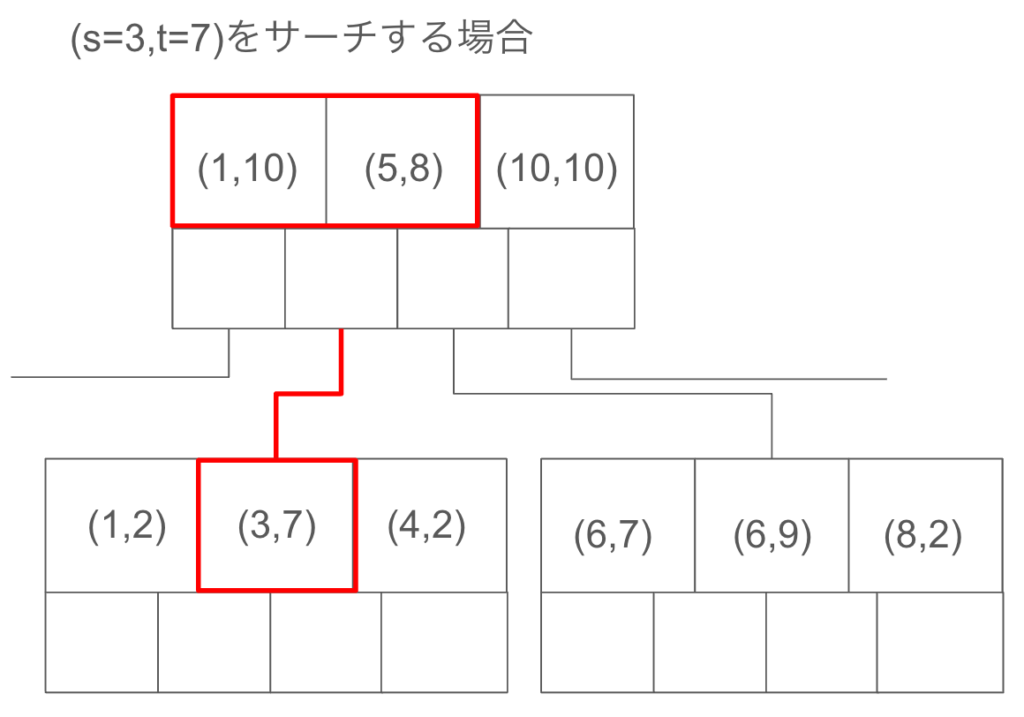
ここで本題です。
2番目のインデックス $t$ のみで検索してみた場合をみてみます。
select * from test_table
where t=7; // tのみで検索この場合、1番目のカラム値でしかソートが保証されていないため、複数のノードに t=7 を満たすレコードが存在する可能性があります。
従って、テーブル全体を見てあげる必要が出てしまい、データ量が多くなるほど時間がかかってしまいます。
まとめ・参考資料
複合インデックスの検索時の注意としてよく言われている件についてまとめました。
- インデックスはB+ツリーというデータ構造で管理され、各ノードはカラム値をソートした状態で管理している。
- 複合インデックスでは1番目のカラム値をソートして管理しており、2番目のカラム値でのみ検索するとテーブル全体のスキャンが必要になる。
参考にした資料をいかに共有します。

